AI-native API gateway engineered for high-performance inference, intelligent routing, and hardware-aware scalability.
A next-generation control layer that unifies API management, AI model orchestration, and GPU-accelerated inference across enterprise environments.
Three-plane architecture separating control, data, and AI inference for scalable, high-efficiency AI systems.
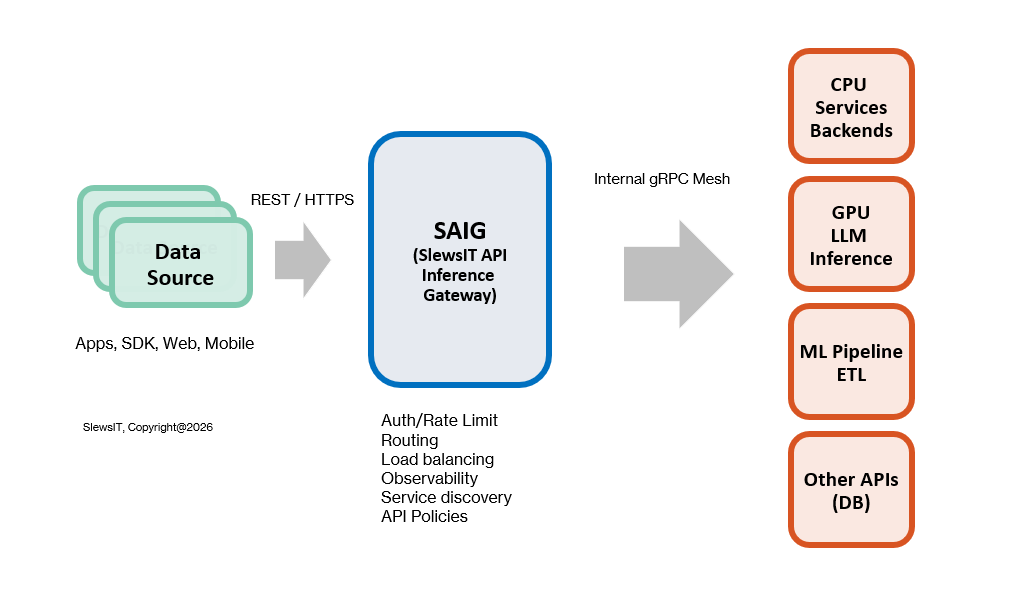
Northbound Interface: REST/HTTPS APIs for application, SDK, and client integration.
Gateway Data Plane: Stateless request processing, routing, load balancing, and streaming inference.
Control Plane: Centralized configuration, service discovery, and traffic policy management.
AI Inference Plane: GPU/CPU-based model execution for LLMs, embeddings, and ML pipelines.
Service Mesh: Internal gRPC communication between gateway and backend services.
Phase 1 – CPU PoC: Go-based gateway with HTTP-to-gRPC bridging and CPU inference backends.
Phase 2 – Scaled Cluster: Horizontally scalable gateway instances with distributed service registry.
Phase 3 – Hardware Accelerated: DPU offload for networking and GPU-based inference for large-scale AI workloads.
An enterprise deploying multiple AI models requires unified access, cost control, and performance optimization.
Outcome: Reduced AI infrastructure cost with improved latency and centralized governance.